
deepnode处理图片_DeepSeek再出新招,图像生成模型超越OpenAI,快来看

出品|搜狐科技作者|郑松毅除夕之夜,DeepSeek 再次震撼发布新模型,为国产大模型领域再添一员猛将北京时间1月28日凌晨,近期备受瞩目的国产大模型新星 DeepSeek,正式发布了其全新开源多模态模型 Janus-Pro,标志着其正式进军文生图领域。
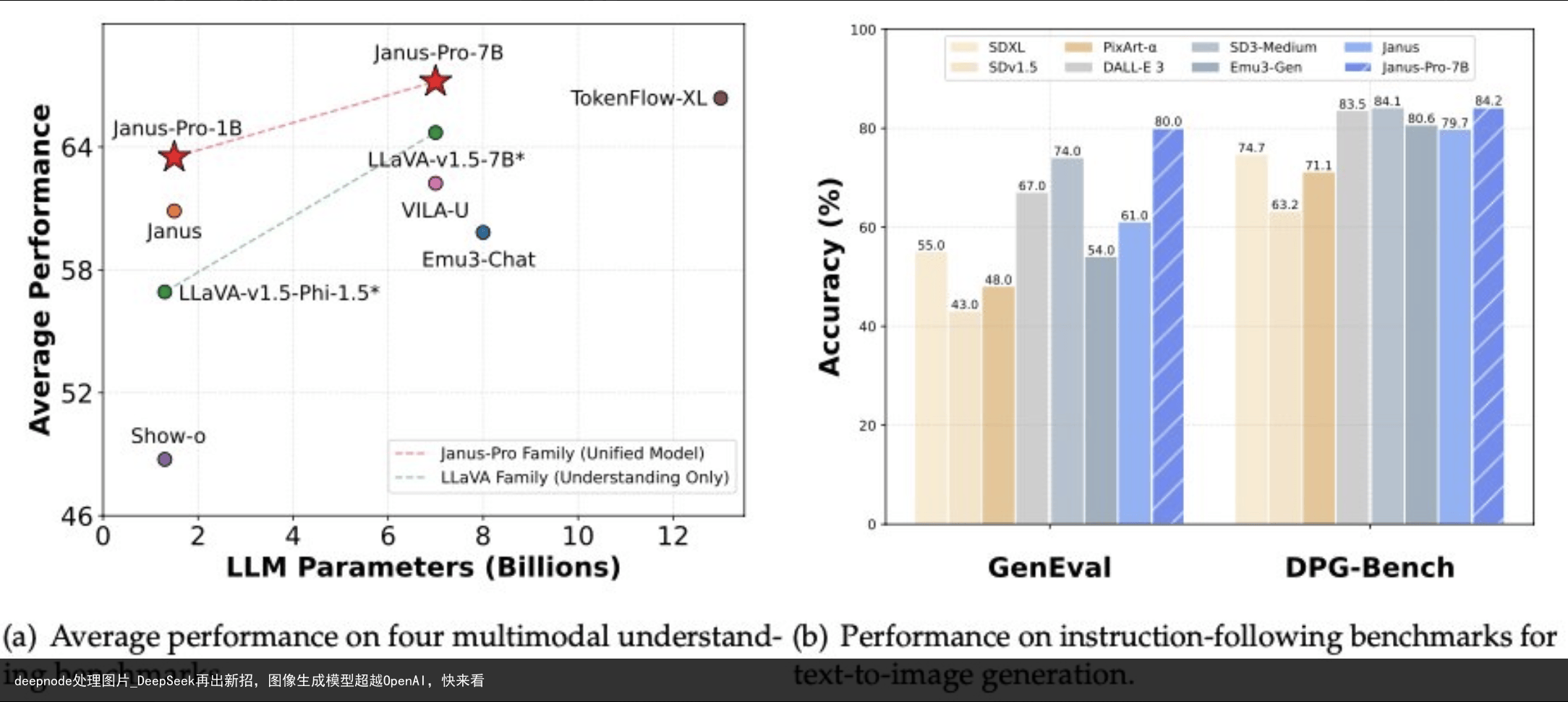
据 DeepSeek 介绍,Janus-Pro 是去年11月发布的 JanusFlow 的升级版本,拥有15亿和70亿参数规模,这意味着这两个模型可以在消费级电脑上本地运行与前一代模型相比,Janus-Pro 在训练策略和数据扩展方面进行了优化,显著提升了图像理解和生成能力。
从测试图来看,Janus-Pro 的图像生成稳定性有了显著提升,能够更加生动地呈现目标人物和物体,色彩饱和度也处理得更加得当。

在识图方面,Janus-Pro 也能根据给定图像进行流畅的描述。

值得一提的是,在文生图 GenEval 和 DPG-Bench 基准测试中,Janus-Pro-7B 模型已经成功击败了 Stable Diffusion 和 OpenAI 的 DALL-E 3 等热门模型。
网友纷纷感叹,“大家还没从 R1 模型带来的震撼中缓过神来,70亿参数规模的多模态模型 Janus-Pro 又让人大开眼界,而且还是开源的新的竞赛开始了!”目前,Janus 系列模型已在 GitHub 平台实现开源,供开发者和研究人员使用,旨在推动文生图生态的进一步发展,并促进相关应用的研究。
新模型,“新”在哪?简而言之,DeepSeek 在 Janus-Pro 中引入了新颖的多模态模型训练框架“视觉编码解耦”,通过将视觉编码分离为“理解”和“生成”两条路径,提升了模型在不同任务中的适配性和性能。
这种“解耦”方法解决了编码器在理解和生成任务中角色冲突的问题,相当于让编码器更专注于各自的任务,从而增强图像理解和生成的稳定性数据方面,Janus-Pro 通过添加7200万张高质量合成图像,实现了真实数据与合成数据比例达到1:1,使得视觉生成效果更具吸引力和稳定性。
【星界云手机】,让你的游戏体验更上一层楼!云端托管手游,挂机脚本助你24小时不间断游戏,让你在游戏中事半功倍,轻松升级打怪,成为游戏世界的领军者!
此外,该模型还参考了 DeepSeek VL2 并增加了约9000万个样本进行多模态理解的训练数据训练方面,DeepSeek 在训练步骤中根据特定比例混合所有数据类型,使用 HAI-LLM 平台进行训练和评估。
整个训练过程在1.5B/7B模型的16/32个节点的集群上花费了7/14天,每个节点配备了8个英伟达 A100 GPU令硅谷和华尔街“震颤”短短一周内,DeepSeek 连续发布 R1 和 Janus-Pro 模型,显然给美国的 AI 技术领先地位带来了巨大压力。
截至1月27日晚,DeepSeek 应用的下载量已超越 ChatGPT,登顶苹果美国区免费 App 下载排行榜长期以来,在大语言模型领域,ChatGPT 系列、Gemini 家族、Claude 等模型处于领先地位。
而在多模态模型领域,Stable Diffusion 和 DALL-E 3 等热门模型备受关注如今,DeepSeek 已在语言模型和多模态模型领域实现了对昔日海外热门模型的赶超,用创新思路打破了“中国 AI 只能跟随”的刻板印象。
从定价策略来看,DeepSeek 系列模型主打性价比,被誉为“AI 界的拼多多”DeepSeek 模型的性能与 GPT-4 相当,但价格仅为后者的1/20DeepSeek 的“不可思议”成绩同样对美国股市产生了冲击,使得一众美国 AI“明星股”纷纷下跌。
截至周一收盘,在满屏“DeepSeek 是什么”的疑问中,纳斯达克综合指数跌3.07%,报19341.83点;标准普尔500指数跌1.46%,报6012.28点其中,英伟达周一收跌16.97%,市值蒸发近5900亿美元,相当于跌出了多于3个 AMD,刷新了美国金融史上的纪录。
福布斯富豪榜显示,英伟达创始人黄仁勋的个人财富在周一蒸发超过208亿美元此外,欧美科技股合计蒸发万亿美元市值,英伟达、博通、台积电等巨头美股盘前纷纷跌超10%“中国不可能永远只是跟随”这句振奋人心的发言,出自 DeepSeek 创始人梁文锋的最新回应。
他表示,“我们经常说中国 AI 和美国有一两年的差距,但真实的差距在于原创和模仿如果这个不改变,中国永远只能是追随者所以有些探索是不可避免的”“过去三十年的 IT 浪潮中,中国基本没有参与真正的技术创新,习惯了‘摩尔定律’从天而降,等待现成的硬件和软件。
但随着经济的发展,中国也要逐步成为技术的‘贡献者’”在这场全球 AI 竞赛中,DeepSeek 没有选择搭已有模型架构的便车,而是选择了创新通过新颖的模型训练架构,进行了更多的尝试对于未来,梁文锋和团队有着清晰的规划,“要参与到全球创新浪潮中去,而不是习惯于拿别人的创新过来,做应用变现。
”澜舟科技创始人兼 CEO 周明发文表示,“DeepSeek 从技术突破到 APP 登顶,不仅成功改写了 AI 行业的发展轨迹,也有力地宣告了大模型轻量化的重要意义和所谓的 Scaling Law 的终结。
”“这是技术极致主义的胜利,更是中国人才智慧与创造力的胜利那些对 OpenAI 亦步亦趋,拿 Scaling Law 欺骗,瞧不起中国人才的所谓大咖可以回去洗洗睡了”Meta 创始人兼 CEO 马克·扎克伯格同样看好中国 AI 技术的发展。
在 DeepSeek 模型发布后,他表示,“DeepSeek 的大模型非常先进,中国正在全力冲刺,美国科技行业虽然暂时领先,但两者差距很小”此外,AI 科技初创公司 Scale AI 创始人亚历山大·王也公开表示,“过去十年来,美国可能一直在人工智能竞赛中领先于中国,但 DeepSeek 的 AI 大模型发布可能会‘改变一切’,尤其是在开源领域。
”
【星界云手机】让你的游戏时光更加充实!云端托管手游,无需担心设备性能、电量损耗等问题,随时畅玩游戏。搭配挂机脚本,让你的游戏之路更加轻松、高效!
本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:631580315@qq.com

